1. Feature Scaling

-
make gradient descent run much faster
-
converge in a lot fewer iterations
-
no need in normal equation method, but while using gradient descent, it’s still important

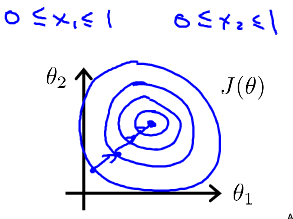
2. Learning Rate α
- α is too small: slow convergence.
-
α is too large: may not decrease on every iteration and thus may not converge.
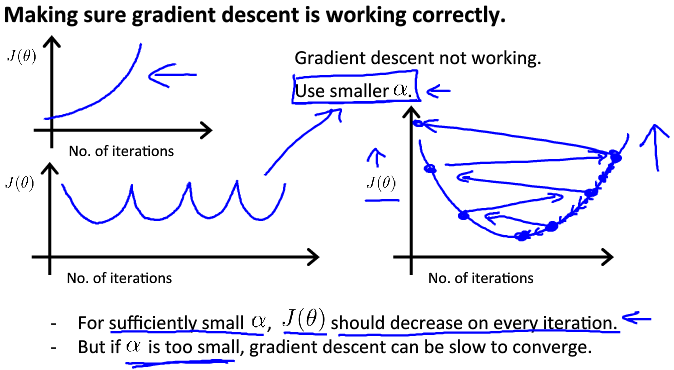
3. Normal equation method
